

Addressing the Predictive Analytics Skills Gap
We are all modelers. Whenever you plan, you are building a model. Whenever you imagine, you are building a model. When you create, write, paint or speak, you first build in your head a model of what you want to accomplish, and then fill in the details with words, movements or other actions in order to realize that model.
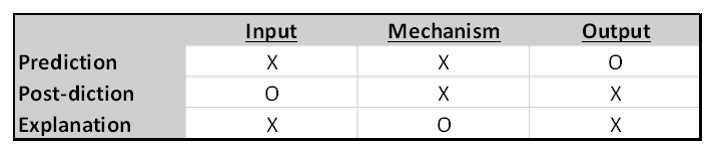
Models work via a three-part structure: Input, Mechanism, and Output. When we use models, we are generally confident in only two of the three stages, and we use the process to determine the unknown stage.
The most familiar construction is where we know, or have confidence in, our inputs and our mechanism (the mechanism being the rules or algorithm that generates output from inputs), which we call “prediction”. We use this structure to predict, or forecast, a wide variety of outputs, from tomorrow’s weather to next month’s sales to next year’s election.
But prediction is not the only available model structure. Operating in reverse, when we are confident in our outputs and our mechanism, but not our inputs, is “retro-diction” or “post-diction”. Instead of asking ‘what will happen?’, this process asks, ‘what sort of inputs could have generated the observed output?’ We use this formulation regularly when we do root cause or failure analysis. In the sciences this structure is commonly employed to discover the possible causes of diseases, or to understand the conditions that might have led to the last ice age or extinction event.
The final model configuration, where we have confidence in both our inputs and outputs, but not in our intervening mechanism, is called “explanation”. What possible mechanism could get us from state A to state B? In the sciences we are always asking what-if questions probing into the structure of plausible mechanisms.
“Explanation” is the model structure we generally have in mind when we ask “why”? Why is the sky blue? (what is the mechanism by which sunlight is differentially scattered?). Why are only certain people resistant to a particular disease? In the social sciences we might ask what mechanisms impact scholastic achievement? In business we might first ask why a certain demographic has different commercial outcomes from another, so that we can later use that more accurate mechanism for predictive purposes.
Each of these modes, however, has its limitations. Forecasts are only as good as the model they are built on. If you are a Weather Channel junkie you know that they use several different models to predict the paths and severity of winter storms and summer hurricanes, knowing that some models will work better than others in certain situations. And your forecast is of course dependent on the quality of the input data used. The field of chaos theory famously grew out of an unintended truncation error in an early weather forecasting model, where dropping the third digit after the decimal point resulted in drastically different results in a matter of just a few days of forecast simulation.
I have already hinted at the primary limitations surrounding retro-diction and explanation – that there can be, and often are, more than one set of inputs, or more than one model, that could give rise to any specified output. The difference between “necessary” and “sufficient”.
Is that all you can do with models? Far from it. There are many other valuable consequences of modeling beyond the Big Three:
- Models can guide data selection, letting you know what data to collect, what data is important to your project.
- Models can suggest useful analogies between and among disparate domains. John von Neumann, the polymath who was at the heart of everything important going on in physics, computer science and mathematics during the 1940s and 50s, was known to memorize those formulas at the end of textbooks, because he found that relationships (i.e. explanatory models) in one field often held the answer to a conundrum in another.
- Discover new questions to ask.
- Demonstrate trade-offs or suggest efficiencies. Building a model of how you do things today can often illuminate how and where to make improvements.
Most importantly, models can be the key to developing an analytic, data-driven culture. When people see that their assumptions must be made explicit and will be questioned, tested and challenged, you are taking a necessary step in instilling the discipline required to become both a more agile and more creative organization. It’s not any particular model or technique, it’s about the entire modeling enterprise and the analytic habits it encourages.
While it is true that we are all modelers, we no longer have to go it alone. We have at our disposal a set ofpowerful analytic tools to augment the model building of our minds, from data quality to data transformation and management, to rapid model prototyping and deployment, to the visualization of output for insight. Every part of the process but one can now reside outside the confines of our limited cranial capacity – the analytic, model-building discipline, and the imagination to apply it, is ours alone to nourish and grow.
By Leo Sadovy, EPM Channel Contributor, from: http://blogs.sas.com/content/valuealley/2015/07/28/why-build-models/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+ValueAlley+%28Value+Alley%29
Leo Sadovy handles marketing for Performance Management at SAS, which includes the areas of budgeting, planning and forecasting, activity-based management, strategy management, and workforce analytics, and advocates for SAS’ best-in-class analytics capability into the office of finance across all industry sectors. Before joining SAS, he spent seven years as Vice-President of Finance for Business Operations for a North American division of Fujitsu, managing a team focused on commercial operations, customer and alliance partnerships, strategic planning, process management, and continuous improvement. During his 13-year tenure at Fujitsu, Leo developed and implemented the ROI model and processes used in all internal investment decisions—and also held senior management positions in finance and marketing.Prior to Fujitsu, Sadovy was with Digital Equipment Corporation for eight years in sales and financial management. He started his management career in laser optics fabrication for Spectra-Physics and later moved into a finance position at the General Dynamics F-16 fighter plant in Fort Worth, Texas.He has an MBA in Finance and a Bachelor’s degree in Marketing. He and his wife Ellen live in North Carolina with their three college-age children, and among his unique life experiences he can count a run for U.S. Congress and two singing performances at Carnegie Hall. See Leo’s articles on EPM Channel here.
Related posts
Excellent article, Leo. Recognizing that all of our decisions are based on our models of reality, not reality itself, is a key to understanding decision making. Too many individuals concentrate their efforts on perfecting “the data” that they then proceed to process through models that have little or no semblance of reality. Good models can still generate quality decision support information when the data is less than perfect, but bad models can only generate misleading decision support information – even when the data is perfect.
As the late Alfred Oxenfeldt wrote; “It is our models of phenomena that determine our behavior, not the phenomena themselves. The validity of our decisions depends on our perception and understanding of reality. Good decisions require good models and the caliber of our decisions reflects the quality and validity of our models.” Data is great, but it cannot become quality, actionable information unless it is processed through a valid model.
Douglass, Your first paragraph is another blog post in itself - probably my topic for next Tuesday. There can be two independent limiting factors when it comes to decision support: the quality of the data, and the quality of the model. Most of the big data hype assumes that the data is pretty much always the limiting factor, and while it may be for a majority of projects, I’d venture that bad or inadequate models share more of the blame than the model builders care to admit. In reality there is likely a desired balance, an evolutionary arms race if you will, where data and models take turns outstripping each other’s capabilities. From my accounting / finance background, we are usually assuming that the quality /quantity of the accounting data is always the limiting factor, often with considerations of diminishing returns on more data, without much consideration for why that might be - which nowadays is the shortcomings of our spreadsheet approach to decision support.